節1. 資料庫架構
例1. 96警2-1.4
DBMS 的資料獨立性(Data Independence)涵義為何?指出資料庫開發所用到的 三個綱要架構(Schema Architecture)名稱。
節2. 資料庫設計階段
節2.1. 資料需求分析
將不同使用者及群體所有相關資訊及需求的搜集。此一階段的主要工作, 就是盡量向使用者蒐集所可能會使用到的資料。
節2.2. 觀念設計(Conceptual design)
對使用者及應用系統(如人事薪資管理系統)的資訊觀點進行模型的建立, 亦即建立
節2.3. 邏輯設計(logical design)
在邏輯設計階段中,係將觀念架構轉換成所選定的DBMS。 例如:關聯式資料庫管理系統的邏輯資料模式(logical data model)
節2.4. 實體設計(physical design)
將邏輯資料模式轉換成某特定硬體及所選用的DBMS所適用的形式, 實體設計係決定資料儲存的結構以及檢索的路徑
節3. 實體關係模型
實體關係模型是1976年Peter Chen發明的資料塑模化方法, 幾乎每場資料庫考試都會出現的基本主題。
例2. 97警2-4
依據學生選課之個體關聯圖,回答以下問題:(30 分)
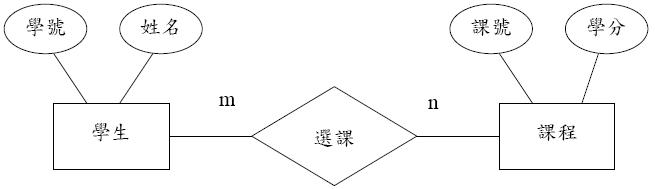
圖1. 學生選課之個體關聯圖
(1)解釋此個體關聯圖的意義。 (2)如何重新繪製此個體關聯圖,以避免出現多對多(m : n)的關聯。 (3)若擬增加一個屬性表示「學生修課的成績」, 則應如何修改題目之個體關聯圖。
答:
(1)
圖1表示一個學生選課模型, 選課為一個二元關係, 參與的實體有學生與課程。 又為一個多對多關係,指一個學生可以選很多課程, 而一個課程也可以讓很多學生選。
學生實體有兩個屬性來描述,分別為學號與姓名, 而課程也有兩個屬性來描述,分別為課號與學分。
(2)
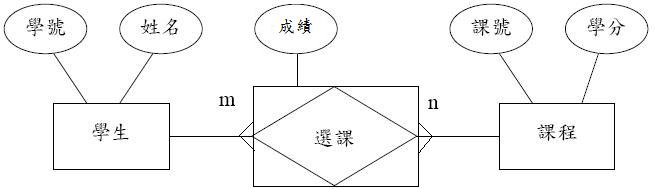
圖2. 去除多對多關係學生選課之個體關聯圖
如圖2所示, 我們去除關係「選課」, 並建立一個關係實體「選課」, 學生與選課為一對多關係, 而課程與選課又也為一對多關係, 這樣便能簡化學生與課程的多對多關係。
(3)
如圖2所示, 我們在「選課」關係實體加入「成績」屬性, 來表示「學生修課的成績」。
節3.1. 實體關係模型基本元素
節3.2. 實體的類型
節3.2.1. 強實體
強實體可獨立存在。
節3.2.2. 弱實體
弱實體不可獨立存在。
節3.2.3. 關係實體
關係實體有二個應用,第一個是簡化多對多關係為二個一對多關係, 第二個是關係具有屬性時,可使用關係實體。
例4. 95關3-2
圖一是個實體關係圖(Entity-Relationship Diagram), 對所用符號的約略說明: 其中每一實體(矩形)鄰近某關係(菱形)間均有一對(min,max)的限制, 代表該實體參與該關係之min(至少)、max(至多)次數限制, *代表沒有限制。屬性畫實底線者為Primary Key(主鍵)的一部分。 該圖要記錄何司機何日駕駛過那一車輛,其該日里程開了多少。 同一司機可能在不同日駕駛過同一車輛, 這就是所謂多重關係(Multiple Relationship)的現象。 請重繪實體關係圖,以去除多重關係的現象。 要求:不得使用高於二元關係(Binary Relationship)之三元或多元關係。 所繪之圖應是最精簡的, 沒有多餘、不必要的實體、關係、屬性。(25 分)
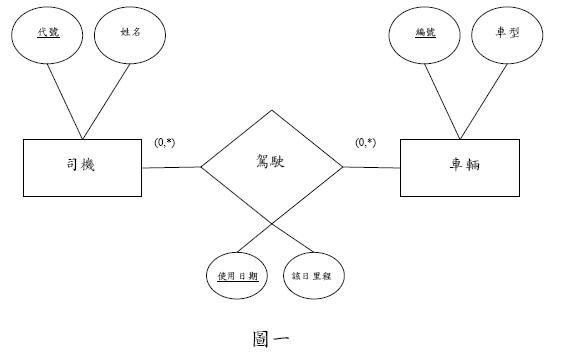
圖3. 多重關係
答:
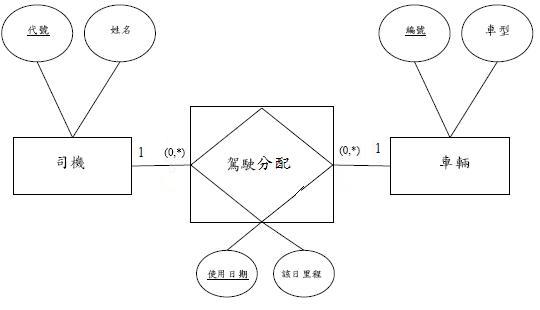
圖4. 去除多重關係
如圖4所示, 我們加入一個關係實體「駕駛分配」, 用來記錄那個司機駕駛那台車, 除了具有司機及車輛的外鍵屬性, 再加上描述分配的使用日期及該日里程的屬性。
司機與駕駛分配為一對多關係, 而車輛與駕駛分配又也為一對多關係, 這樣便能簡化司機與車輛的多對多關係。
節3.3. 關係的度數
關係的度數指得是參與關係的實體數目, 或是關係所連結的實體數目。 一般分為一元、二元及三元關係。
節3.3.1. 一元關係
一元關係就是遞迴關係,參與的實體數目只有一個。
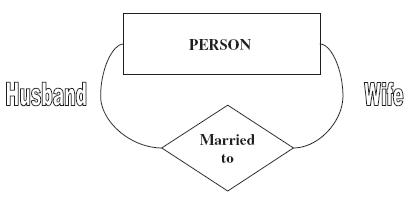
圖5. 婚姻關係
如圖5Married to關係就是一元關係, 參與的實體只有 PERSON,通常會在連結關係的線上加上註記, 此註記稱為角色,Married to 有兩個角色,分別是 Husband 及 Wife。
節3.3.2. 二元關係
二元關係參與的實體數目有二個。 如圖1選課關係就是二元關係, 參與的實體有學生與課程。
節3.3.3. 三元關係
三元關係參與的實體數目有三個, 只有二元關係無法表示語意時,才會使用三元關係。
節3.3.4. 四元關係
四元關係參與的實體數目有四個, 只有三元關係無法表示語意時,才會使用四元關係。
節3.4. 關係的基數
關係的基數指得是參與關係實體的實例個數, 分為一對一關係、一對多關係及多對多關係。
節3.4.1. 一對一關係
一對一關係指一個實例只關聯到另一個實例。
節3.4.2. 一對多關係
一對多關係一個實例關聯到多個實例。
一對多的關係通常會使用Master/Detail報表來顯示資料, 例如一家出版商可能會出版多本書, 通常程式能瀏覽所有的出版商,也就是 Master 報表, 同時另外還可以檢視個別出版商所出版的書籍,也就是 Detail 報表。
節3.4.3. 多對多關係
多對多關係多個實例關聯到多個實例。 如圖1所示,一個學生可以選很多課程, 而一個課程也可以讓很多學生選。
節3.4.4. 多對一關係
多對一關係多個實例關聯到一個實例。
節3.4.5. 基數限制條件
如圖3所示, 可以在實體與其關係間加入(min,max)的基數限制條件, 代表該實體參與該關係之min(至少)、max(至多)次數限制, *代表沒有限制, 來進一步標示實體允許參與關係的範圍。
節3.5. 關係的參與限制
參與限制指定實體的實例是全部或部分參與關係, 可以分為兩種。
節3.5.1. 完全參與限制
所有實體集合的實例都參與關聯性, 使用雙線來標示,也稱為「存在相依」。
節3.5.2. 部分參與限制
在實體集合只有部分實例參與關聯性,使用單線標示。
節3.6. 屬性的類型
屬性是一組值的集合, 這些值是屬性可能的值, 稱為值集合(Value Set)或定義域(Domain)。 屬性可以分成很多種,如下所示:
節3.6.1. 簡單屬性
這是實體與關係的基本屬性, 只擁有簡單值, 用一個橢圓形來表示。
如圖1所示, 課程的課號與學分都是簡單屬性。
節3.6.2. 複合屬性
屬性是由多個簡單屬性組成, 使用樹狀的簡單屬性橢圓形符號來表示。
節3.6.3. 多值屬性
屬性值不是簡單值,而是多重值, 使用雙線的橢圓形節點符號來標示。
節3.6.4. 導出屬性
這是一種可以由其它屬性計算出的屬性, 使用虛線的橢圓形節點符號來標示。
節3.6.5. 識別屬性
如果屬性是實體中用來識別實例的屬性, 其角色相當於關聯表的主鍵, 識別屬性是在名稱下加上底線來標示。
如圖6所示, 警察人員的實例可由身份證字號來唯一識別。
節3.7. 增強型實體關係模型
增強型實體關係模型為在原本的實體關係模型加上階層關係。 適合去表示具有階層關係的領域。
等式1. 增強型實體關係模型
增強型實體關係模型 = 實體關係模型 + 階層關係
節3.7.1. 超類型與子類型
參與階層關係的實體分為超類型與子類型, 子類型的實體一定被包含於超類型中, 如圖6中, 行政警察、交通警察及刑事警察都可以為警察人員, 所以行政警察、交通警察及刑事警察是警察人員的子類型, 而警察人員是行政警察、交通警察及刑事警察的超類型,
節3.7.2. 一般化與特殊化
一般化與特殊化是指設計階層關係的流程, 這兩個流程概念相同,但是方向不同。
特殊化是由超類型開始,並辨識出實例中的不同特徵, 藉由這個相異來細分成幾個子類型。
一般化是歸納幾個子類型的共同屬性, 再建立一個超類型來表達這些共同屬性。
如圖6中, 若從警察人員的實例中, 辨識出行政警察、交通警察及刑事警察的相異特徵, 再分別建立上述的子類型,即為特殊化。 若先辨識出行政警察、交通警察及刑事警察的共同特徵, 再建立它們的超類型警察人員,就為一般化。
節3.7.3. ISA 關係
階層關係是由 ISA 關係(簡寫 ISA)表示, ISA 支援屬性繼承及關係參與, 屬性繼承子類型會繼承所有超類型的屬性。 如圖6中,使用圓形來表示 ISA。 關係線為直線加上 U,數學中表示屬於的符號, 由 U 的方向來分別子類型與超類型。 因為行政警察、交通警察及刑事警察是警察人員的子類型, 屬性繼承使行政警察、 交通警察及刑事警察都具有其超類型, 警察人員的身份證字號。
節3.7.4. 多重繼承
一個子類型若同時繼承一個以上的超類型稱為多重繼承。
節3.7.5. 一般化與特殊化的屬性
一般化與特殊化的屬性可由兩個問題區分:
分離性(Disjointness):超類型的一個實例是否可同時為二個以上子類型的實例?
若是則其屬性為重疊性,反之則為分離性。
完全性(completeness):超類型的一個實例是否一定要為一個以上子類型的實例?
若是則其屬性為完全性,反之則為部份性。
節3.7.5.1. 分離性
節3.7.5.2. 重疊性
在特殊化過程中,若超類型的一個實例可為二個以上子類型的實例, 則此特殊化稱為重疊的。
節3.7.5.3. 完全特殊化
在特殊化過程中,若超類型的一個實例一定要為一個以上子類型的實例, 則此特殊化稱為完全特殊化。
節3.7.5.4. 部份特殊化
在特殊化過程中,若超類型的一個實例不一定要為子類型的實例, 則此特殊化稱為部份特殊化。
例5. 96警2-3
下圖為有關「警察人事」資料庫之超類型/子類型關係圖。
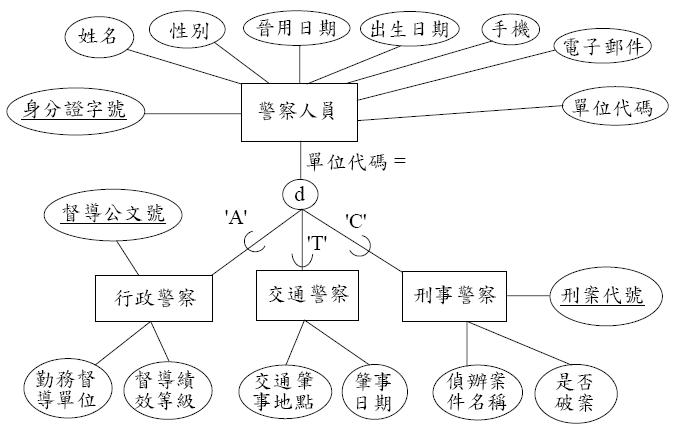
圖6. 「警察人事」資料庫之超類型/子類型關係圖
答:
(1)請參考節3.7.5。
(2)請參考節3.7.1。
(3)轉成相對的表格如下
表1. 警察人員
| 警察人員 | |||||||||||||||
| 身份證字號 | 姓名 | 性別 | 晉用日期 | 出生日期 | 手機 | 電子郵件 | 單位代碼 | 督導公文號 | 勤務督導單位 | 督導績效等級 | 交通肇事地點 | 肇事日期 | 刑案代號 | 偵辦案件名稱 | 是否破案 |
如表1所示, 型態階層所有實體的屬性都加入到「警察人員」這個基礎表中, 並使用「單位代碼」作為識別紀錄型態的型態辨識欄位。 這就是所謂的單表繼承。
(4)依單表繼承,子型態的欄位都要可為空值,故表格之 DDL 如下:
程式碼1. 建立警察人員表格
create table "警察人員" ( "身份證字號" varchar(10) not null, "姓名" varchar(100) not null, "性別" varchar(1) not null, "晉用日期" date not null, "出生日期" date not null, "手機" varchar(20) not null, "電子郵件" varchar(255) not null, "單位代碼" varchar(1) not null, "督導公文號" varchar(20), "勤務督導單位" varchar(20), "督導公文號" varchar(20), "勤務督導單位" varchar(255), "督導績效等級" int, "交通肇事地點" varchar(255), "肇事日期" date, "刑案代號" varchar(2), "偵辦案件名稱" varchar(255), "是否破案" varchar(1), primary key ("身份證字號") );
節3.8. 實體關係圖的常見錯誤
因錯誤解釋實體間的關係造成實體關聯圖的錯誤, 稱為「連接陷阱」(Connection Traps)。 實體關聯圖最常見的兩種連接陷阱錯誤,如下所示: 扇形陷阱(Fan Traps)。 斷層陷阱(Chasm Traps)。
例6. 95高2-2
假設有員工(Employee)、 部門(Department)與專案(Project)三個個體, 其個體關係圖(ER-Model)如圖一, 試問此個體關係圖可能產生何種錯誤陷阱?試舉例說明。(20 分)
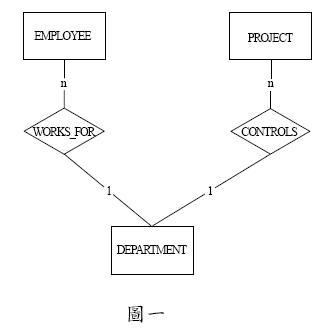
圖7. 扇形陷阱
答:請參閱節3.8.1。
節3.8.1. 扇形陷阱
扇形陷阱(Fan Traps)通常產生在實體擁有多個一對多的關係, 如同風扇形散開,使實體間關係令人混淆的問題。
如圖7所示, DEPARTMENT 實體擁有 2 個一對多關係, 一個 DEPARTMENT 有多個 EMPLOYEE 為工作。 一個 DEPARTMENT 控制多個 PROJECT。
但是 EMPLOYEE 為那個 PROJECT 工作是混淆的, EMPLOYEE 不會為部門所有的 PROJECT 工作, 可以只為 3 個 PROJECT 工作。
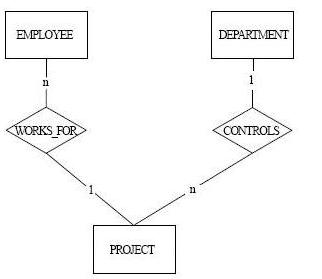
圖8. 解決扇形陷阱
關係正確的解釋應該是以 PROJECT 建立橋樑關係。 如圖8所示, 確立 EMPLOYEE 為那個 PROJECT 工作的關係後, 再由一個 DEPARTMENT 控制多個 PROJECT 的關係, 便可連接一個 DEPARTMENT 有多個 EMPLOYEE 為工作的關係。
節3.8.2. 斷層陷阱
斷層陷阱是指實體間應該存在的關聯根本不存在, 兩個實體間並沒有辦法找到一條路徑來連接。 通常發生在部份參與的實例。
斷層陷阱的解決方式是新增關係,
節3.9. 實體關係模型與自然語言
關係的度數指得是參與關係的實體數目, 或是關係所連結的實體數目。 一般分為一元、二元及三元關係。
表2. 實體關係模型與自然語言
| 英文文法結構 | 實體關聯圖結構 |
| 普通名詞(Common Noun) | 實體型態(Entity Type) |
| 專有名詞(Proper Noun) | 實體(Entity) |
| 及物動詞(Transitive Verb) | 關聯型態(Relationship Type) |
| 不及物動詞(Intransitive Verb) | 屬性型態(Attribute Type) |
| 形容詞(Adjective) | 實體的屬性(Attribute) |
| 副詞(Adverb) | 關聯性的屬性(Attribute) |
節4. 關聯式模型
關聯式模型依照 CJ Date 的說法, 包含三個主要項目, 分別是物件、完整性及運算子。
節4.1. 物件
節4.1.1. 定義域
定義域類似程式語言中的資料型態, 為一群值的集合, 可用來定義了表格的某個欄位所允許的可能值, 也是模型表達真實世界的最小描述單位。
相同定義域的物件便可以比較。
節4.1.2. 表格
表格是資料庫中儲存資料的基本架構。 分為欄位(column)及列(row)。 每一列代表一筆紀錄,而每一欄代表一筆紀錄的一部份。 舉例來說,如果我們有一個記載顧客資料的表格, 那欄位就有可能包括姓、名、地址、城市、國家、 生日等等。 所以定義表格時,需要註明欄位的標題, 以及那個欄位的資料類型。
表格可視為一群{欄位:值對}的集合。
節4.1.3. 表格變數
表格變數是可以指向一個表格物件的變數。
節4.2. 關連式代數
E.F.Codd 對於關連式代數最原始的定義中包含了八個運算, 分為兩組,集合運算子及特殊運算子。
表格式運算子至少接受一個表格運算元, 且運算結果均為一個表格, 表式表格式運算子是封閉的, 所以幾個運算子可以組成套疊公式, 以基礎運算比擬,加法、減法及乘法在整數下是封閉的, 使得運算元及結果都為整數,所以可組成套疊公式。
程式碼2. 文法
expr := monadic | dyadic monadic := renaming| restriction | projection renaming := term RENAME col as col term := table | (expr) restriction := term WHERE codition projection := term | term[c1,c2,...] dyadic := projection dop expr dop := UNION | INTERSECT | MINUS | TIMES | JOIN | DIVEDBY
節4.2.1. 集合運算子
集合運算子都為二元運算子, 接受二個表格型態的運算元,並傳回一個結果表格。
節4.2.1.1. 積
運算以集合論中所定義的「卡式積」, 將兩個表格組合成一個表格, 這個是理論基礎上的運算子,在實務上是避免這種使用方式的。
節4.2.1.2. 聯集
此運算以集合論中所定義的聯集,從兩個表格中取出聯集的資料, 重複的資料只取出一筆。
節4.2.1.3. 交集
此運算以集合論中所定義的交集, 即將兩個表格中欄位相同的資料集成一個表格
節4.2.1.4. 差集
此運算以集合論中所定義的差集運算, 從一個表格中刪除另一個表格中有的資料。
節4.2.2. 特殊運算子
節4.2.2.1. 限制
從一個表格中取出符合條件的紀錄。
程式碼3. 相等條件
suppliers where city='高雄'
上述代數式表示取出位於高雄的供應商。
條件是作用於某個定義域上布林函數, 像是程式碼3中的條件為相等條件, 若某紀錄的 city 欄位值等於右端的’高雄’字串, 則此紀錄會被選擇出來。
程式碼4. 範圍條件
suppliers where id < 100
上述代數式表示取出位於供應商編號小於 100 的所有供應商。 此類條件稱為範圍條件,用來測試值是否符合指定範圍, 分別有大於、小於、大於等於及小於等於, 對應的符號分別為 ’>’, ’<’, ‘>=’ 及 ‘<=’。
程式碼5. 布林運算子
suppliers where id < 100 and city='高雄'
上述代數式表示取出位於供應商編號小於 100 且位於高雄的所有供應商。 因為條件都是布林函數,所以可以用布林運算子串接。
程式碼6. 集合運算等式
suppliers where city='高雄' intersect suppliers where id < 100
節4.2.2.2. 投影
從一個表格中取出所需要的欄位。
程式碼7. projection
R[id, name]
上述代數式表示取出供應商的編號及名稱組成新的表格。
節4.2.2.3. 除法
除法運算有兩個運算元: 第一個表格當作是「被除表」, 第二個表格當作是「除表」。 被除表的欄位必須要比除表多上一個以上, 令被除表欄位 num 為 X1,X2…,Y1,Y2…, 而除表欄位 den 為 Y1,Y2…, 則 num DIVIDEBY den 的欄位應為 X1,X2…, 而結果紀錄的 X1,X2… 為在原本的 num 中的具有 den Y1,Y2…。
除法可類比為乘法的還原運算,如下等式所示。
- num = quo TIMES den
- quo = num DIVIDEBY den
通常除法會運用在找出符合 den 所有紀錄的語法, 如程式碼8的例子, 表示找出供應所有原料的供應商編號。
程式碼8. 找出供應所有原料的供應商編號
suppliers_parts[s_id, p_id] DIVIDEBY parts[id as p_id]
下面是另外一個例子,employees 記錄員工資料, skills 記錄技能資料,
employees_skills記錄員工所會的技能, 則可用 DIVIDEBY 取得會所有技能的員工姓名。
程式碼9. 找出會所有技能的員工姓名
(employees_skills[e_id, s_id] DIVIDEBY skills[id as s_id] JOIN employees)[name]
節4.2.2.4. 外部合併
外部合併是作用在兩個表格上的運算子, 其將表格分成主表格及副表格, 原本相等合併除去所有不滿足合併條件的列, 而外部合併則保留主表格的所有列, 若沒有副表格的列則副表格的欄位設為 NULL 值。 左外部合併運算子其左方表格的是主表格, 右方表格為副表格; 右外部合併運算子其右方表格的是主表格, 左方表格為副表格。
節4.2.3. 原始運算子
原始運算子無法以其他的運算子來定義, 而非原始運算子可由原始運算子上述推演出來。 原始運算子包含:
- UNION
- MINUS
- TIMES
- PROJECT
- RESTRICT
非原始運算子包含:
- INTERSECT
- JOIN
- DIVIDEBY
「原始運算子」這些運算子無法以其他的運算子來定義。
表3. 關連式代數與關連式計算的比較
| 關連式代數 | 關連式計算 | |
| 1 | 為一程序式的查詢語言。 | 為一非程序式查詢語言。 |
| 2 | 必須明白地指出運算的順序。 | 不須明白地指出運算的順序。 |
| 3 | 必須提供基本運算。 | 不須提供基本運算。 |
| 4 | 以集合的基本運算與表格式運子為基礎。 | 以集合表示法與 predicate calculus 為基礎。 |
| 5 | 表示能力與關連式計算相等,而且每一個關連式代數的查詢皆可轉成相對的關連式計算查詢。 | 表示能力與關連式代數相等,而且每一個關連式計算的查詢皆可轉成相對的關連式代數查詢。 |
| 6 | 可直接實現,並可作為查詢最佳化時的樹狀結構中間型式。 | 通常是以轉成關連式代數來實現。 |
節4.3. 關聯式完整性
完整性是資料庫設計的一部分, 表示整個資料庫要遵守的限制, 尚新增或更新紀錄違反資料庫所定義的完整性時, 資料庫系統會禁止此項操作, 其目的是檢查並保障資料庫儲存是否準確的限制, 並避免表格間資料不一致。
節4.3.1. 定義域完整性限制
定義域定義了某個欄位所允許的可能值, 表格的欄位值一定是屬於定義域的單元值。
SQL 除了資料型態支持定義域, 還能再加入 check 限制來更進一步限制資料型態的可能值, 請參閱節5.2.2.5
節4.3.1.1. 空值完整性限制
空值完整性用來限制某個欄位是否可為空值。
節4.3.2. 主鍵
節4.3.2.1. 超鍵
超鍵(Superkeys)是表格中單一欄位或一組欄位的集合, 超鍵需要滿足唯一性(Uniqueness),在表格絕不會有 2 個值組擁有相同值, 只需透過超鍵的識別,就可以在表格存取指定的值組。
節4.3.2.2. 候選鍵
在每一個表格至少擁有一個候選鍵(Candidate Keys), 候選鍵是一個超鍵,不只滿足超鍵的唯一性, 還需要滿足最小性(Minimality),最小欄位數的超鍵, 在超鍵中沒有一個欄位可以刪除, 否則將違反唯一性。 表格的候選鍵需要同時滿足唯一性和最小性,簡單的說, 候選鍵是最小欄位數的超鍵,所以單一欄位的超鍵一定是候選鍵。
節4.3.2.3. 主鍵
主鍵(Primary Key, PK)是表格各候選鍵中的其中之一, 而且只有一個,它是用來唯一定址表格中的一筆紀錄。
在眾多候選鍵中如何挑選主鍵,選擇原則如下:
絕對不是空值(Not Null):候選鍵的欄位值不能是空值, 如果是複合鍵,所有欄位都保證不會是空值。
永遠不會改變(Never Change):候選鍵的欄位值永遠不會改變。
本身不是識別值(Nonidentifying Value):候選鍵的欄位值本身沒有其他意義, 與原本資料沒有關係的欄位, 通常是人造欄位。
簡短且簡單的值(Brevity and Simplicity):儘可能選擇單一欄位的候選鍵。
在 SQL 中,可用 primary key 用來定義主鍵, 請參見節5.2.2.1。
節4.3.2.4. 替代鍵
在候選鍵中不是主鍵的其他候選鍵稱為替代鍵(Alternate Keys), 因為這些是可以用來替代主鍵的侯選鍵。
節4.3.2.5. 組合鍵
主鍵可以包含一或多個欄位。 當主鍵包含多個欄位時, 稱為組合鍵 (Composite Key)。
節4.3.2.6. 鍵限制
鍵限制規定表格要有一個滿足唯一性和最小性的主鍵。
節4.3.2.7. 實體完整性限制
表格主鍵不可為空值, 因為一個實體至少須滿足能與其它實體區別的限制。
節4.3.3. 參考完整性限制
所有表格的外鍵,其所參考表格的主鍵必須存在, 否則為空值,表示未參考任何實體。
節4.3.3.1. 外鍵
外鍵(Foreign Keys, FK)是表格的單一欄位或一組欄位的集合, 它的值是參考其他表格的主鍵,也可能是參考同一個表格的主鍵。
它和其他表格的主鍵是對應的, 在關聯式資料庫是扮演連結表格的膠水功能,
它和參考的主鍵屬於相同定義域,不過欄位名稱可以不同,
外鍵在表格內不一定是主鍵。
參考主鍵中的主鍵如果是單一欄位,外鍵就是單一欄位, 參考主鍵是組合鍵,外鍵也必須是組合鍵。
外鍵可以是空值。
在 SQL 中,可用 foreign key 用來定義外鍵, 請參見節5.2.2.2。
例7. 96高2-3
例8. 96警2-4
為確保資料庫內的資料能正確被處理, 遵循完整性法則(Integrity Rules)是有其必要的。 請回答下列各問題:
寫出實體與參考完整性法則內涵。(8 分)
DBMS 除了支援參考完整性外,還可能支援包括預設值、 檢查範圍與NULL等完整性控制。 試寫出後面三個完整性控制的主要用途, 並利用SQL CREATE TABLE statement 舉出實例。(9 分)
根據下面兩個關聯表(CrimeBK與CrimeCase), 利用SQL CREATE TABLE statement 來建立相對應的資料表, 以確保資料庫資料的完整性。(註:資料型別與長度可自訂)(8 分)
表4. Crime_BK
| ID | CName | Gender | Birth_of_Date |
表5. Crime_Case
| CrimeNo | CrimeType | Crime_Event_Date | ID | Crim_BK.ID | Crime_Case.ID |
答:
(1)
節4.4. 函數相依性
當在表格找出所有關位間的函數相依後,就可以幫助我們在表格找出: 重複資料,一些不該屬於此表格的欄位; 候選鍵和主鍵, 如果表格的所有欄位都函數相依於一個或一組欄位, 這個欄位就是候選鍵(Candidate Key)或主鍵(Primary Key)。
定義1. 函數相依
令 R 為一個欄位集,A, B 屬於 R, 若表格 R 的 t1 和 t2 值組滿足 t1(A) = t2(A), 則一定滿足 t1(B) = t2(B)。 則稱 A 定義 B 或 B 函數相依於 A, 記作 A → B。
節4.4.1. 阿姆斯壯公理
阿姆斯壯公理是作用在函數相依上的推論規則 包含下面三條推論規則:
定義2. 反身性規則
若 a 是一個欄位集,且 a 包含 b,則 a → b。
定義3. 擴充性規則
若 a → b 且 c 是一個欄位集,則 ac → bc。
定義4. 遞移性規則
若 a → b 且 b → c,則 a → c。
定理1. 阿姆斯壯公理是健全的
定理2. 阿姆斯壯公理是完備的
節4.4.2. 相關定理
定理3. 自我定義
a → a
證明:
因為 a 包含 a,所以 a → a。
定理4. 分解
定理5. 聯集
定理6. 組合
定理7. 虛擬遞移性
若 a → b 且 bc → d,則 ac → d 。
節4.4.3. 函數相依封閉集
定義5. 函數相依封閉集
令 F 為一組函數相依, 則 F 的函數相依封閉集 F+ 為應用阿姆斯壯公理衍生的所有函數相依集合, 且 F+ 無法再衍生出新的函數相依。
定義6. 欄位封閉集
令 F 為表格 T 的一組函數相依, C 為表格 T 的欄位集, 則 C 的欄位封閉集 C+ 為以 C 為定義域並在函數相依下的最大值域欄位集, 且 C+ 無法再加入新的欄位。
程式碼10. 計算欄位封閉集
require 'set' def attr_closure a,fds i,c=0,[a] loop do i+=1 c[i]=c[i-1] fds.each_pair do |l,r| if c[i].superset? l c[i] += r end end break if c[i] == c[i-1] end c[i] end
如程式碼10所示, 可以很簡單的用電腦算出欄位封閉集。
因為欄位封閉集可以很簡單的用電腦算出來, 便能用來測試某個函數相依是否為某函數相依封閉集裡, 如定理8所示。
定理8. 測試函數相依
令 S 為一組函數相依,FD: X→Y 為一個函數相依, 則若 FD 屬於 S,則 Y 必為 X 在 S 下的 X+ 的子集。
欄位封閉集也可用來判斷某欄位集是否為超鍵, 如定理9所示。
定理9. 測試超鍵
令 S 為表格 T 的一組函數相依, C 為 T 的一組欄位集, 若 C+ 等於 T 的所有欄位, 則 C 為 T 的超鍵。
例9. 95關3-1
假設某Relational Database Schema 為 R(A,B,C,D,E,F,G) 其功能依賴(Functional Dependencies) 為
- {A,B}→C
- {C,D}→E
- {D,E}→{B,F}
- F→G
- G→D 請以功能依賴的推論(Inferences)規則,來回答: 說明{A,B}是否為Candidate Key?(10 分) 找出所有R 之Candidate Key。(15 分)
答:
(1)
先計算{A,B}的屬性封閉集 {A,B}+,
- {A,B}→C
- {A,B}→{A,B,C}
由上可發現右方沒有 {A},{B},{C},{A,B},{A,C},{B,C},{A,B,C} 等自變集,所以 {A,B}+ = {A,B,C}, 而非{A,B,C,D,E,F,G},故 {A,B} 並非 Candidate Key。
(2)
- {A,B}+ = {A,B,C}
- {A,B,C}+ = {A,B,C}
- {A,B,D}+ = {A,B,C,D,E,F,G}
- {A,B,E}+ = {A,B,C,E}
- {A,B,F}+ = {A,B,C,D,E,F,G}
- {A,B,G}+ = {A,B,C,D,E,F,G}
- {D,E}+ = {B,D,E,F,G}
- {A,D,E}+ = {A,B,C,D,E,F,G}
- {A,F,E}+ = {A,B,C,D,E,F,G}
- {A,G,E}+ = {A,B,C,D,E,F,G}
由以上的屬性封閉集可得 {A,B,D}, {A,B,F}, {A,B,G},{A,D,E},{A,F,E},{A,G,E} 為 Candidate Key。
節4.4.4. 最簡函數相依
若是表格 T 的一組函數相依集 S 具有下列性質:
- S 中每個函數相依 FD:X→Y,值域 Y 只有一個欄位。
- X 是最簡,也就是刪除 X 任何一個欄位會改變 S+。
- S 是最簡的,若刪除 S 中任何一個 FD 會改變 S+。
我們稱 S 為 T 的最簡函數相依。
節4.5. 正規化
節4.5.1. 關連表異常
表6. 資料重覆的表格
| 客戶帳號 | 客戶名稱 | 地區編號 | 地區名稱 |
|---|---|---|---|
| 01 | 台積電 | 2 | 新竹市 |
| 02 | 聯電 | 2 | 新竹市 |
| 03 | 中華電信 | 1 | 台北市 |
| 04 | 成大醫院 | 3 | 台南市 |
| 05 | 台大醫院 | 1 | 台北市 |
上表可看出,地區編號若為 1,則地區名稱一定為台北市, 地區編號若為 2 則地區名稱一定為新竹市, 這樣稱表為資料重覆。 資料重覆會引發幾個異常:
節4.5.1.1. 刪除異常
若刪除客戶帳戶 04,則失去了台南市及其地區編號為 3 的資訊, 相同的未插入客戶帳戶 04,永遠不會知道台南市及其地區編號為 3。
節4.5.1.2. 更新異常
若更客戶帳戶 05 的地區名稱為新竹市,也要連帶更改其地區編號為 2, 或者想要使新竹市的地區編號為 6 則必須更改客戶帳戶為 01 02 的記錄。
節4.5.2. 無損分解
若關連表 R 分解成 A 及 B 表,若 A,B 能經由關連式運算組成表 R, 則稱 {A, B} 為 R 的無損分解(Lossless Decomposition)。
若將上表分解成以下兩表
表7. 有損分解
| 客戶帳號 | 客戶名稱 | 地區編號 | 客戶帳號 | 地區名稱 | |
| 01 | 台積電 | 2 | 01 | 新竹市 | |
| 02 | 聯電 | 2 | 02 | 新竹市 | |
| 03 | 中華電信 | 1 | 03 | 台北市 | |
| 04 | 成大醫院 | 3 | 成大醫院 | 台南市 | |
| 05 | 台大醫院 | 1 | 05 | 台北市 |
節4.5.3. 第一正規化
將非純量欄位化成新的表格 去除重覆群組
節4.5.4. 第二正規化
去除部份相關
節4.5.5. 第三正規化
去除部份遞移相關
節4.5.6. BCNF
去除因函數相關產生的異常
例10. 97警2-3
舉例說明為何需要正規化(Normalization)?舉例說明如何達成第三階正規化型式 (3NF)?舉例說明正規化可能有何缺點?(20 分)
節5. SQL 語言
SQL 語法是以關聯式代數作為基礎的, SQL 指令包含資料定義語言(DDL)、資料處理語言 (DML)、資料控制語言(DCL)和交易控制語言(TCL)。
節5.1. SQL 語言功能
DDL 用來新增、更改或刪除資料庫中的物件, 包括表格、使用者、索引等物件, 指令包括:
- create
- alter
- drop
- truncate
- comment
- rename
DML 讓使用者新增、擷取、更改或刪除資料庫中的紀錄, 上述的操作簡寫為 CRUD, 指令包括:
- select
- insert
- update
- delete。
DCL 用來定義使用者操作資料庫物件的權限, 指令包括:
- grant
- deny
TCL 用來控制資料庫的交易, 指令包括:
- commit
- savepoint
- rollback
- set transaction
例11. 96高2-3
SQL 指令包含資料定義語言(DDL)、資料控制語言(DCL)和資料處理語言 (DML)三種,試簡單說明並至少各舉三個指令。(30 分)
答:請參見節5.1
例12. 95關3-3
三、假設某關連資料庫(Relational Database )中有兩個表格(Tables)分別儲存「調 查員」(Investigator)、「獎勵」(Reward)。其Schema 如下: Investigator(SID,Name,BirthDate,Region) 屬性分別代表調查員「編號」、「姓名」、「生日」、「地區」,而以「編號」 為其主鍵(Primary Key)。「姓名」是另一候選鍵(Candidate Key)。“Region" 值可能為「台北市」、「高雄市」等中文字串。 Reward (Number,Date,Affairs,Amount) 屬性分別代表「調查員編號」、「獎勵日期」、「獎勵事蹟」、「獎勵金額」, 而以「調查員編號」、「獎勵日期」合在一起為其主鍵。「獎勵金額」最少是 1000 元。獎勵是固定每個月在月中15 日辦一次,所以「獎勵日期」會出現如 2005 年5 月15 日、如2005 年7 月15 日等數值。 請寫出下列查詢之SQL: 請找出在「台北市」地區的調查員人數。(10 分) 對每位受過二次以上獎勵的調查員,請列出其調查員「編號」、「姓名」。 (10 分) 對在「台北市」地區的調查員,接受過最高獎勵的金額為多少?(10 分)
例13. 96高2-4
在關聯式資料庫中,兩個資料表做聯結(Join)運算時,為什麼有些資料會遺失? 應如何避免?(20 分)
節5.2. DDL
節5.2.1. 定義表格
表格是資料庫中儲存資料的基本架構。 分為欄位(column)及列(row)。 每一列代表一筆紀錄,而每一欄代表一筆紀錄的一部份。
舉例來說,如果我們有一個記載顧客資料的表格, 那欄位就有可能包括姓、名、地址、城市、國家、 生日等等。 所以定義表格時,需要註明欄位的標題, 以及那個欄位的資料類型。
程式碼11. create table
create table customers (first_name char(50), last_name char(50), address char(50), city char(50), country char(25), birth_date date)
節5.2.1.1. 刪除表格欄位
刪除表格 customers 的欄位 city 須用 alter table , 如程式碼12所示。
程式碼12. drop column
alter table customers drop column(city);
節5.2.2. 定義完整性
如節4.3所述, 完整性是確保資料正確性的方法, 完整性包含在表格定義中, 完整性限制可以在表格藉由 create table 語句來指定, 或是之後藉由 alter table 語句來指定。
常見的限制有以下幾種:
- primary key
- foreign key
- not null
- unique
- check
節5.2.2.1. primary key
primary key 用來定義主鍵,請參見節4.3.2.3。
我們可以運用 create table 於建置新表格時設定主鍵, 如程式碼13所示
程式碼13. create primary key
create table customer (id integer, last_name varchar(30), first_name varchar(30), primary key (id));
以下則是以 alter table 來設定主鍵的方式:
程式碼14. alter primary key
alter table customer add primary key (id);
請注意,在用 alter table 來添加主鍵之前, 我們需要確認被用來當做主鍵的欄位是設定為 not null, 也就是說,那個欄位一定不能沒有資料。
節5.2.2.2. foreign key
foreign key 用來定義參考完整性,請參見節4.3.3。
假設有兩個表格: 一個 customer 表格, 裡面記錄了所有顧客的資料; 另一個 orders 表格,裡面記錄了所有顧客訂購的資料。 在這裡的一個限制,就是所有的訂購資料中的顧客, 都一定是要跟在 customer 表格中存在。 在這裡,我們就會在 orders 表格中設定一個外鍵, 而這個外鍵是指向 customer 表格中的主鍵。 這樣一來,我們就可以確定所有在 orders 表格中的顧客都存在 customer 表格中。 換句話說,orders表格之中,不能有任何顧客是不存在於 customer 表格中的資料。
我們可以在 create table 語法指定外鍵, 如 程式碼16 所示, orders 表格中的 customerid 欄位是一個指向 customers 表格中 id 欄位的外鍵。
程式碼15. create foreign key
create table orders (order_id integer, order_date date, customer_sid integer, amount double, primary key (order_id), foreign key (customer_id) references customer(id));
假設 orders 表格已經被建置,但外鍵尚未被指定, 則可利用 alter table 來指定外鍵,如 程式碼16 所示。
程式碼16. alter foreign key
alter table orders add foreign key (customer_id) references customer(id);
節5.2.2.3. not null
一個欄位預設是允許有 null, 如果不允許一個欄位含有 null, 就需要對那個欄位做出 not null 的指定。
程式碼17. not null
create table customer (id integer not null, last_name varchar (30) not null, first_name varchar(30));
如程式碼17指出 id 和 lastname 不允許有 null, 而 firstname 可以有 null。
請注意,一個被指定為主鍵的欄位也一定會含有 not null 的特性。 相對來說,一個 not null 的欄位並不一定會是一個主鍵。
節5.2.2.4. unique
unique 限制是保證一個欄位沒有重複值。
程式碼18. unique
create table customer (id integer unique, last_name varchar (30), first_name varchar(30));
如程式碼18指出 id 欄位不能有重複值存在, 而 lastname 及 firstname 這兩個欄位則是允許有重複值存在。
請注意,一個被指定為主鍵的欄位也一定會含有 unique 的特性。 相對來說,一個 unique 的欄位並不一定會是一個主鍵。
節5.2.2.5. check
check 限制是保證一個欄位中的所有資料都是符合某些條件。
程式碼19. check
create table customer (id integer check (id > 0), last_name varchar (30), first_name varchar(30));
id 欄只能包含大於 0 的整數。
許多系統並未實作 check,例如 MySQL 資料庫上。
節5.3. 資料操作語言
節5.3.1. 投影、別名
投影就是將抽取表格上的欄位,組合成新的表格。 在 SQL 中,我們是利用 select 來完成此項運算。
程式碼20. select 語法
select [distinct] *|cex1,cex2... from table;
字元 * 表示選取所有的欄位
若於 select 後加入 distinct 修飾,則合併重覆欄.
cex=colasalias 其中 col 為欄位名,alias 為欄位的別名, as 字可加可不加.
程式碼21. 投影 SQL
select id, name from suppliers
程式碼22. 選取所有欄位
select * from suppliers;
選出 suppliers 所有的欄位.
程式碼23. select ex3
select distinct id, name, deptno from emp;
從 emp 表中,選出 id, name 及 deptno 三欄成為新表, 並合併重覆欄.
節5.3.2. 限制
限制運算以 SQL 表示如程式碼24, 在 where 字後面加上條件, 此 SQL 表示取出位於高雄的供應商。
程式碼24. restriction sql
select * from suppliers
where city='高雄'
節5.3.3. 合併
節5.3.4. 卡積
節5.3.5. 集合運算子
節5.3.6. 摘要
節5.3.7. 進階的 group 功能
rollup 及 cube 是 Oracle8i 之後版本才支援。
節5.3.7.1. rollup
程式碼25. rollup 語法
select [key_columns], group_function(column) from table [where conditions] group by ROLLUP(columns) [having having_conditions] [order by key_columns]
此運算子能夠自動產生小計列,其產生小計是 keycolumns 由右至左分層依次產生小計列。
若 columns 個數為 n ,則一個 rollup 等於 (n+1) select。 Ex. 在阮醫院的 opd 資料庫
程式碼26. rollup 例子
select a.curr_dept_id dept, a.curr_title_id title, count(*) t from hiatt0090 a group by rollup(a.curr_dept_id, a.curr_title_id)
等於下列 3 行 select
程式碼27. rollup 等式
select a.curr_dept_id dept, a.curr_title_id title, count(*) t from hiatt0090 a group by a.curr_dept_id, a.curr_title_id union all select a.curr_dept_id dept, '' title,count(*) t from hiatt0090 a group by a.curr_dept_id union all select '' dept, '' title, count(*) t from hiatt0090 a order by dept, title
節5.3.7.2. cube
程式碼28. cube 語法
select [key_columns], group_function(column) from table [where conditions] group by CUBE(columns) [having having_conditions]
此運算子能夠自動產生小計列,除與 rollup 一樣是由 keycolumns 由右至左分層依次產生小計列,並在後面 由左至右再產生一次小計列。
grouping 函數以 rollup 的 columns 作為參數,若此 行其參數欄為為小計層次,則傳為 1,否則為 0。
節5.3.8. 統計函數
例14. 96警2-1.2
查詢有關資料庫名稱為「CrimeDB」與資料表名稱為「重大刑案」內資料行(或 欄位)名稱為「犯罪類別」,持有“擄人勒贖"的總筆數。
答:
程式碼29. 96警2-1.2
select count(*) from CrimeDB.'重大刑案' case where case.'犯罪類別' = '擄人勒贖'
節6. 實體關係圖轉關聯式表格
節6.1. 為每個強實體建立一個表格
節6.2. 為每個弱實體建立一個表格
為每個弱實體都建立一個表格,表格名稱為實體名稱。
把每個簡單屬性加入表格,並設欄位名稱為屬性名稱。
將擁有者的識別屬性加入至表格,並設為外鍵。
擁有者的識別屬性及其本身的部份識別屬性合成表格的主鍵。
節6.3. 為每個多值屬性建一個表格
為多值屬性建一個表格, 表格名稱為實體名稱加上底線,再加上屬性名稱。
為表格新增參考到實體識別屬性的外鍵, 並將實體的識別屬性加入成為主鍵,
為表格新增表示屬性本身一個值的欄位,其名稱同屬性名稱。
設定表格的主鍵為外鍵加上多值屬性。
如果多值屬性為複合屬性, 可能需要加上其中一個屬性或是全部屬性。
節6.4. 一對多關係的轉換
關係可以在表格新增參考其它實體的外鍵來表示。 一對多關係轉換成表格的規則,如下所示:
在 N 端的表格新增參考到 1 端表格的外鍵, 若關係擁有簡單屬性,也一併加入新增外鍵的表格。
節6.5. 一對一關係的轉換
一對一關係是一對多關係的特例, 轉換規則如下所示:
每個參與關係的表格新增參考到參與關係另一個表格的外鍵, 若關係擁有簡單屬性,也一併加入新增外鍵的表格中。
節6.6. 多對多關係的轉換
如圖2所示, 先把多對多關係用關係實體簡化多對多關係為二個一對多關係。
為關係建立新的表格,名稱為關係名稱。
為表格加入兩個外鍵,分別參考到參與關係的二個實體。
若關係具有屬性, 為表格新增表示屬性本身一個值的欄位,其名稱同屬性名稱。
將表格主鍵設為兩外鍵的組合鍵。 另一個取向是另外為關係建立唯一識別的主鍵, 因為有時兩外鍵的組合鍵無法唯一識別關係實體。
節6.7. 一對多單元關係的轉換
單元關係就是遞迴關係, 其轉換可分為一對多及多對多, 一對多單元關係的轉換規則如下:
先建立表示參與實體的表格。
再為表格加入一個外鍵參考到本身實體的主鍵, 且欄位名稱命名為”關係名id”。
節6.8. 多元關係的轉換
多元關係的轉換規則如下:
為關係建立表格,名稱是關係的名稱。
為表格加入外鍵分別參考參與的實體。
若關係擁有簡單屬性,也一併加入新建立的表格綱要。
把所有外鍵的組合鍵設為表格主鍵, 另一個取向是另外為關係建立唯一識別的主鍵, 因為有時所有外鍵的組合鍵無法唯一識別關係實體。
節6.9. 繼承關係的轉換
繼承關係第一種表示法, 是在子型態的表格中加入指向超型態實體表格的外鍵。
另一種表示稱為單表繼承(STI,Single Table Inheritance), 由 RoR 的 ActiveRecord 採用。
單表繼承第一步是建立一個表示型態階層的基本表格, 並命名為型態階層根實體的名稱。
把型態階層所有實體的屬性加入此表格, 而非所有型態所共享的屬性要能存放空值。
最後在此表格加入一個型態欄位, 或指定一個根型態屬性作為型態辨識欄位。
實例請參見例5。
單表繼承最大的好處是節省很多表格串接的動作, 效率較高。
節7. 交易
單元性(Atomic): 交易內的操作,不是全部執行,就是全部不執行。 若單元內其中一個操作未完成,則整個交易必須回到初始狀態, 回到初始狀態的程序稱為復原(Recovery, Rollback)。
一致性(Consistency): 交易前後資料的必須維持一致。 像是銀行的轉帳,轉帳兩帳戶其金額加總在轉帳前後必須相等。
隔離性(Isolation): 對交易外的操作而言,只能看到交易的兩種終止狀態,初始及交付。 這意指交易排程(Transaction Schedule) 必須維持可序列化(Serializable)。 為了資料庫效能,隔離性通常會比較寬鬆。
持久性(Durability): 一旦交付,則交易狀態會永久保存且不能復原。
目前的計算機組織採用雙層式的記憶體, 分別為隨機存取記憶體 (RAM,Random Access Memory) 及磁碟, RAM 存取快,但電源關閉則資料狀態就消失, 磁碟存取慢,但可保存寫入的資料狀態,不會因電源關閉而消失, 通常 CPU 可以直接存取 RAM 的資料, 而 CPU 在讀取磁碟資料時, 會先載入(load)磁碟資料到 RAM,再從 RAM 讀取(read)載入的資料; CPU 寫入資料到磁碟時, 會先寫入(write)資料到 RAM, 再儲存(store)RAM 中的資料到磁碟。 故在此機制下,交易要達到交付狀態, 即是保證交易的所有資料操作的結果, 已經寫入到磁碟,才能達到單元性及持久性的需求。
節8. 並行控制
例15. 97警2-1
名詞解釋:請儘可能舉例說明。(30 分) (1)綱要(Schema) (2)並行控制(Concurrency Control) (3)候選鍵(Candidate Key) (4)預儲程序(Stored Procedures) (5)嵌入式SQL(Embedded SQL) (6)回復(Rollback)
節8.1. 時戳並行控制
時戳並行控制的基本邏輯如下: 當一個交易欲存取某一個資料物件, 會比較自已與資料物件上的讀取時戳, 來確認存取動作順序不會違反可序列化順序, 若交易動作違反條件,則會立即放棄並重新啟動交易。
時戳(timestamp)表示一個即時時刻, 且無任兩個時戳相等。 每個交易開始時,會立刻印上一個時戳, 稱為交易時戳, Ti.ts 表示交易 Ti的交易時戳。 每個資料庫物件會有兩個時戳, 讀取時戳和寫入時戳 分別在讀取或寫入物件時印上其執行者的交易時戳, Oi.rts及 Oi.wts 分別表示資料物件的讀取時戳及寫入時戳。
資料庫若維持一致,應滿足以下條件: 若動作 Ai 和 Aj 互為衝突動作, 且 Ai 為交易 Ti 的動作, Aj 為交易 Tj 的動作, 若 Ti.ts < Tj.ts, 則 Ai 應比 Aj 早執行。
若違反上述條件,應立即放棄並重新啟動交易, 這和鎖定並行控制不同,其會暫停交易,等待至可以繼續交易。
依上述限制,交易 T 正要讀取物件 O 時,應有下面的行為:
若 T.ts < O.wts則 T 立即放棄並重新啟動交易。 令 Tw 表示最後寫入 O 的交易, 上面則意指T.ts < Tw.ts, 由於 T.r(O) 與 Tw.w(O) 互為衝突動作, 故依上述限制 T.r(O) 必須早於 Tw.w(O), 所以讀取物件 O 的動作違反上述限制,T 立即放棄並重新啟動交易。
其餘情況則 T 讀取 O, 並重設 O.rts=max(T.ts, O.rts)。
依上述限制,交易 T 正要寫入物件 O 時,應有下面的行為:
若 T.ts < O.rts則 T 立即放棄並重新啟動交易。
若 T.ts < O.wts則 T 立即放棄,但不重新啟動。
這是湯瑪式寫入法則(Thomas Write Rule), 一個衝突可序列化排程 “pic/thomaswriterule1.png” 另一個衝突可序列化排程 pic/thomaswriterule2.png” 如上兩圖,若 T1.ts < T2.ts, 則 T1 對 A 的寫入會被 T2 對 A 的寫入取代, 但不會造成衝突動作,故可以忽略 T1 對 A 的寫入。
其餘情況則 T 寫入 O, 並重設 O.wts=T.ts。
這與上述正要讀取物件不同在於, 讀取可以讓很多交易同時進行,所以其 O.rts 可能會大於 T.ts, 但寫入永遠只能一個,所以直接將 O.wts 設為 T.ts
節8.2. 鎖定並行控制
鎖定並行控制的基本邏輯如下: 當一個交易欲存取某一個資料物件, 必須具取得此資料物件的鎖定, 否則需等待至其它交易釋放其鎖定, 才能進行存取動作。
節9. 物件導向資料庫
物件導向資料庫(Object-Oriented Database), 純粹 OOP 中的物件,在程式結束後,就消失了,而 SQL 等語言, 操作的都是存續(Persist)的資料, 所以 OO 資料庫便是擴充 OOP 使得裡面的物件具在存續的功能。 一般而言擴充的方式如下:
宣告類別有存續功能
標記物件為存續物件
利用交易物件來存續物件
節9.1. 物件關連資料庫
物件關連資料庫(Object-Relational Database) 是擴充原本的 SQL 能定義複雜物件型態,巢狀關連等。
節9.2. 可擴展標記語言(XML)
節10. 資料探堪
例16. 96警2-2
在警察刑事之資料庫知識探索 (Knowledge Discovery in Database,KDD)程序上, 常會用到資料轉換(Data Transformation)。 有關「最小值-最大值正規化法」 (Min-Max Normalization)資料轉換公式如下: * oldMax - oldMin newValue = newMax - newMin (OriginalValue - oldMin)+ newMin 其中oldMax 與oldMin 分別代表資料庫之資料表內某一資料行的最大值與最小值; newMax 與newMin 分別為正規化後的最大值與最小值。現考慮一個名叫「CrimeDB」 的資料庫與其內含一個名叫「CrimeTable」的資料表,此資料表之資料行名稱、資 料型別、Null 與限制如下: 資料行名稱 資料型別 允許Null 限制 ID nvarchar(10) (不允許) Primary key CName nvarchar(8) 無 Age int 無 Age01 float (允許) 無 試以關聯式DBMS SQL 語法與名為spNormalization 的預存程序(Stored Procedure),撰寫預存程序功能如下:(20 分) 建立CrimeTable 資料表。 新增四筆(ID, CName, Age)資料,分別為(A120999121, 王黑白, 32)、 (G124994120, 林大家, 25)、(V223456787, 王妃妃, 51)、(S123456787, 張老大, 33)。 將Age 年齡值轉換成落在0 與1 之間,並將轉換值存入Age01 內,以便可供 資料採礦(Data Mining)類神經網路處理之用。 將CrimeTable 所有資料行資料依ID 排序顯示在螢幕上。 撰寫「建立CrimeDB 資料庫,呼叫spNormalization」的程式碼。(5 分)
節11. 資料保護
例17. 97警2-2
何謂非對稱加密(Asymmetric Encryption)? 舉例說明如何將它應用於建立數位簽章(Digital Signatures)。(20 分)
